

Спостережуваність — одна з тих тем, де галузева дискусія катастрофічно розходиться з реальними потребами більшості команд. Великі постачальники продають платформи, розраховані на флоти сервісів і відповідний штат для їх обслуговування. Маленькі команди, які цілком обґрунтовано не довіряють такому рахунку, врешті випускають продукт з console.log і надією, що в неділю нічого не зламається. Обидва полюси помиляються в один бік.
Чесна оцінка така: є двотижневий обсяг робіт зі спостережуваності, що окупається протягом усього життя системи, і набагато більший пласт після нього, який починає виправдовувати себе лише тоді, коли у вас з'являється масштаб, щоб ним користуватися. Виграють ті команди, які встигають закрити перший обсяг до того, як він знадобиться, і не піддаються спокусі другого, поки реальна потреба не настане.
Ось як виглядає цей перший обсяг — у тому порядку, в якому ми його будуємо.
Структуровані логи з ідентифікатором запиту
Це найбільш важлива зміна, яку може зробити невелика система, і саме її більшість команд пропускає, бо прототип уже «має логування». Не має — принаймні в тому розумінні, що дійсно важливе.
Потрібен JSON-вихід, одна подія на рядок, зі стабільним набором ключів: timestamp, level, service, request_id, user_id, де доречно, та повідомлення. Кожен внутрішній перехід — HTTP-виклик між сервісами, фонове завдання, запущене з запиту, запит до бази даних, що вартий трасування, — несе той самий request_id далі. Middleware, що його генерує, — це один файл. Робота полягає в дисципліні передавання цього ідентифікатора всюди.
Щойно це налаштовано, досвід зневадження змінює природу. Користувач повідомляє, що оплата провалилась о 14:32. Ви робите grep request_id=... по всіх потоках логів і отримуєте повну історію по порядку: запит надійшов, потрапив у API, викликав платіжний воркер, воркер не дочекався відповіді від зовнішнього сервісу, API повернув 502, фронтенд показав не те повідомлення про помилку. Раніше така історія потребувала годину звіряння часових міток у трьох терміналах. Тепер — три секунди. Помножте це на кожен інцидент, який система колись матиме, і аргументація на користь структурованих логів пише сама себе.
Неструктуровані логи, навпаки, занепадають. Першого дня вони виглядають прийнятно і стають непридатними тієї миті, коли у вас більше одного сервісу або більше одного інженера.
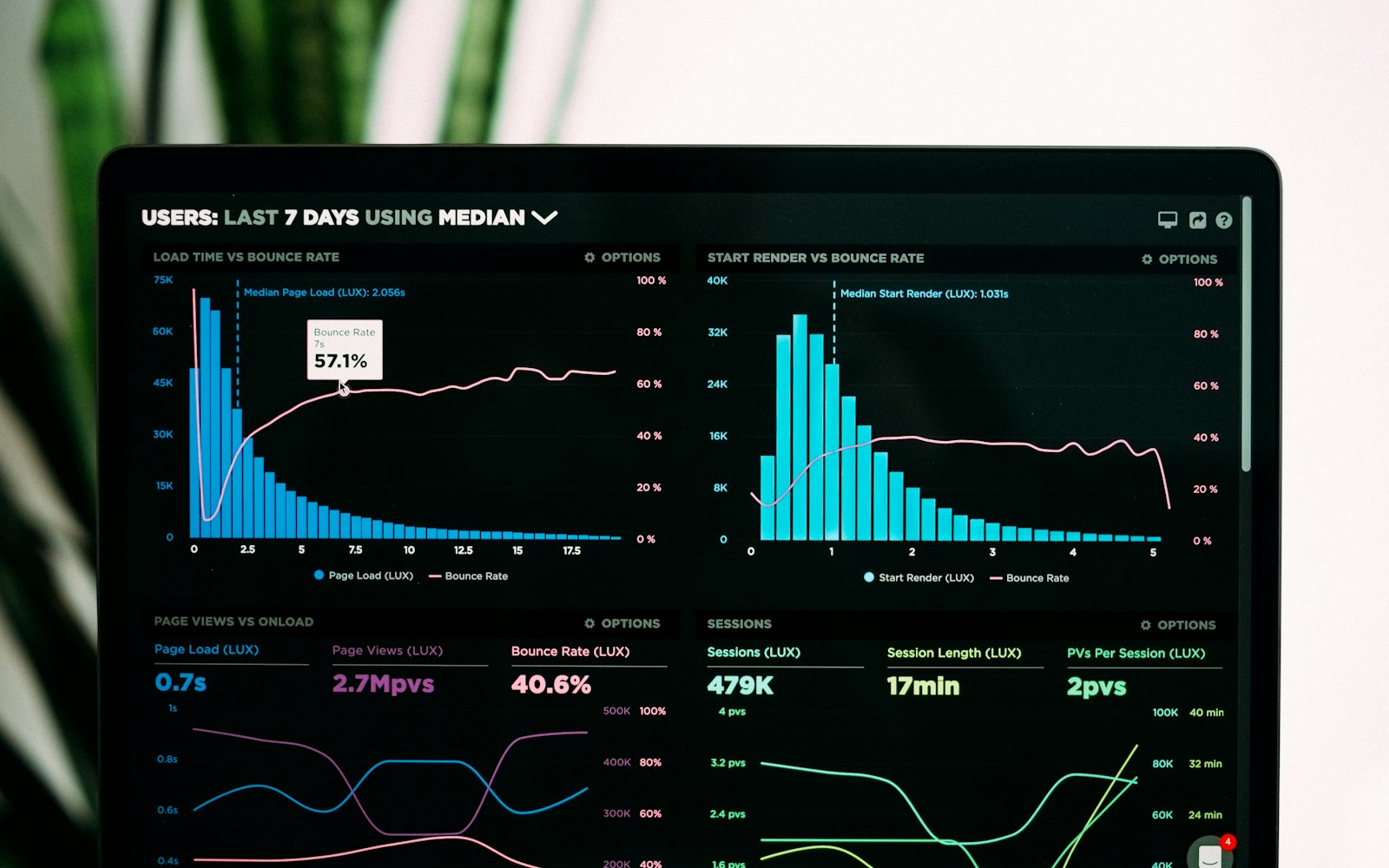
Одна панель моніторингу
Не двадцять. Одна.
Помилка, яку робить кожна команда після того, як відкриває для себе інструмент метрик, — будувати окрему панель на кожен сервіс, кожну команду, кожен аспект, а потім зверху ще «головну» панель, що зв'язує їх усі. Жодна з них не читається. Панель, що виправдовує своє існування, — це та, яку втомлений інженер може відкрити на телефоні об 11 вечора і прочитати за три секунди.
Що на неї виноситься: p95 та p99 затримки на кожен публічний ендпоінт, частота помилок на ендпоінт, глибина черги для будь-якого асинхронного воркера, кількість повільних запитів за останні п'ять хвилин. Можливо, одна продуктова метрика, якщо є єдина цифра, що означає «продукт працює», — оплати за хвилину, реєстрації за годину, що там у вашому випадку. І все.
Дисципліна не у побудові панелі. Вона в тому, щоб не додавати ті вісімнадцять інших графіків, які хтось запропонував на нараді. Кожен доданий графік удвічі зменшує ймовірність, що панель взагалі прочитають. Команда, яка не може прочитати її за три секунди, — це команда, яка її не читатиме.
Сповіщення в канал, який реально читає людина
Папки в електронній пошті не рахуються. Папки в електронній пошті — це цвинтар сповіщень. Канал має бути таким, який конкретна людина перевіряє в проміжок часу, протягом якого сповіщення взагалі має сенс: Slack, Discord, PagerDuty, якщо у вас є чергування, або навіть SMS для важких випадків.
Складніша дисципліна, на порядок складніша, — це чистка. Перший тиждень після підключення сповіщень вас заллє потоком. Спокуса завжди — додавати ще, бо кожне виглядає так, ніби ловить щось справжнє. Реальна робота — видаляти ті, що спрацьовують без дії з боку команди, ті, які всі вчаться змахувати геть. Сповіщення, яке змахнули тричі поспіль, перестало бути сповіщенням. Це шум, що сховає справжнє сповіщення, коли воно прийде.
Планка, яку ми тримаємо: кожне сповіщення відповідає або кроку інструкції реагування (runbook), або «розбудити людину». Якщо не підходить ні те, ні те — це не сповіщення, це графік на панелі.
Дві іменовані інструкції реагування
Напишіть дві інструкції реагування (runbooks) до першого інциденту. «База даних лежить» і «релізи зламані». По одній сторінці на кожну. Звичайна проза: кроки, які ви робитимете, команди, які запускатимете, люди, яким телефонуватимете.
Чому дві, а не десять: перші дві покривають більшість ранніх інцидентів, які ви реально побачите. Інструкція, написана до інциденту, корисна. Інструкція, написана під час інциденту, — це художня література. Сенс написати їх раніше — не в повноті. Він у тому, щоб змусити команду подивитись на припущення, зашиті в систему, поки всі ще достатньо спокійні, щоб думати.
Побічна користь: нові інженери можуть прочитати ці дві сторінки в перший день і зрозуміти про те, як система реально ламається, більше, ніж за три тижні нарад з архітектури.
Чим ми не займаємось
Це мінімум. За його межами лежить довгий список речей, що справді окупаються на масштабі та справді не окупаються на малому.
Розподілене трасування — канонічний приклад. OpenTelemetry — чудова технологія. Для системи з двох сервісів і одного воркера це накладні витрати, що дають дуже мало понад те, що вже забезпечують структуровані логи зі спільним ідентифікатором запиту. Того дня, коли у вас вісім сервісів і історія через request_id перестане вміщатися на одному екрані, трасування стане необхідним. До цього моменту — це податок.
Кастомні метрики на кожну операцію — те саме. Інстинкт інструментувати все виглядає як ретельність, а здебільшого є просто захаращенням. Метрики виправдовують себе, коли у вас достатньо трафіку, щоб цифри були статистично осмисленими, і достатньо інженерів, щоб хтось реально на них дивився.
Формальні SLO з бюджетами помилок — інструмент для організацій, достатньо великих, щоб розмова «випускати фічу чи гасити борг по надійності» потребувала числа як точки опори. Для команди з п'яти людей це розмова. Додавання SLO-машинерії не робить відповідь кращою — лише додає церемонії.
Нічого з цього не є аргументом проти самих інструментів. Це аргумент за послідовність. Вони окупляться пізніше, і «пізніше» має значення, бо ціна занадто раннього впровадження — це ціна того, що чотири речі вище не доведено до кінця.
Чому команди це пропускають
Команди пропускають мінімум не тому, що не розуміють його цінності. Вони пропускають, бо наступного дня після запуску нічого видимо не ламається. Система без структурованих логів, без панелі, без сповіщень і без інструкцій реагування виглядає ідентично до тієї, що має всі чотири, — аж до першого справжнього інциденту.
Шкодують про це з тієї простої причини, що день, коли воно ламається, — це день, коли відповідь можна було б отримати за три кліки, а замість того йде шість годин детективної роботи, вибачальний лист клієнтам і ранкова розмова в понеділок про те, чому ніхто цього не побачив наперед.
Два тижні зосередженої роботи, повернені протягом усього життя системи. Ми будуємо це за замовчуванням на старті кожного проєкту, який беремо в роботу. Ніхто цього не рекламує. Воно потрібне всім.